

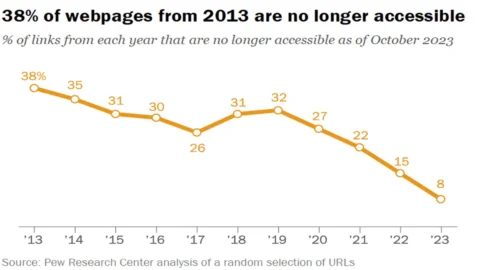
38% of web pages existing in 2013 are no longer accessible ten years after creation. He says it a study by the US research center "Pew", which provides information on social problems, public opinion and demographic trends. To fully understand the meaning of the outcome of this analysis it is necessary, first of all, to establish what is meant by "pages no longer accessible” and define the data extraction criterion.
The starting point is the sample used. These are the pages taken from the web repository of Common crawl, a non-profit organization that crawls the entire web and provides its archives and datasets to the public for free. The archive consists of petabytes of data collected since 2008. Typically, scans are completed every month, so Pew researchers had to take and analyze carefully 120 packages, each corresponding to a month of a specific year starting from 2013 and up to 2023. The analysis therefore requires a comparison, certainly not carried out by a person, but rather by a software routines (created using the Python programming language), between the content present at a certain address and corresponding to a particular date and the content present today at the same address. The outcome of this test cannot give results other than:
- error 204 (no content)
- error 400 (bad request)
- 404 error (page not found)
- error 410 (page removed)
- error 500 (internal server error)
- error 501 (error in request method)
- error 502 (connection error)
- error 503 (service unavailable)
- error 523 (content source unreachable)
or from:
- page slightly modified
- page radically modified
- address that refers to another content (moved page) which can fall into the 2 previous cases.
In the sample there are only:
- pages from government websites (identified via .gov domain provider data)
- news sites (identified using data from audience metrics company “comScore”)
- pages of the online encyclopedia Wikipedia
- pages of individual public posts on the social media X/Twitter
To compile the report, the researchers focused only on the coded errors (from error 204 to error 523), i.e. on pages that are truly no longer available in any way, for various reasons. Other definitions of accessibility are beyond the scope of the research. The pages were then considered accessible in all other cases, including ambiguous situations where the existence of the content could not be guaranteed, such as “soft 404” pages or timeouts not caused by DNS (i.e. waiting times too long to retrieve the original pages).
The objective conclusions of the study are that approximately a quarter of all web pages existing between 2013 and 2023 are no longer accessible (in the sense indicated above) starting from October 2023. In most cases, this is due to the fact that a single page has been deleted or removed on an otherwise functioning website. That is, it is the individual content that has been deleted, not the entire site.
For example, 23% of news web pages contain at least one broken link, as do 21% of government site web pages. News sites with a high level of traffic and those with a lower level are equally likely to contain broken links. It is particularly likely that the government web pages at the local level (those belonging to city administrations) contain broken links. The 54% of Wikipedia pages contains at least one link in the “references” section that points to a page that no longer exists. On X/Twitter, almost one in five tweets is no longer publicly visible, even just a few months after being published. In 60% of these cases, the account that originally posted the tweet was made private, suspended, or deleted altogether. In the remaining 40%, the account owner has deleted the individual tweet, but the account still exists. Some types of tweets tend to disappear more often than others. Over 40% of tweets written in Turkish or Arabic they are no longer visible on the site within three months of publication. And tweets from accounts with default profile settings are more likely to disappear from public view.
What do these data mean?
Once again, a premise is needed: we cannot exclude that there may have been some classification errors of data labeled as “not available”. This is because, for security reasons, some sites actively try to prevent the type of automated data collection that was achieved through this investigation. Having said this, the reasons, more than legitimate and which should not cause any concern or regret, why a page disappears from the Internet within 10 years, can be:
- removal under European data protection law (GDPR)
- removal pursuant to and for the purposes of the decision of the Court of Justice of the European Union (CJEU) relating to the right to be forgotten
- removal imposed by law in general (defamation, causing alarm, clandestine press, abusive practice of various professions, etc...)
- removal due to content no longer valid and lack of updates in this regard
- expiration of the information contained within the pages
- Paid landing page, no longer used
- failure to pay for domain maintenance
- violation of copyright
- lack of funds to support an editorial project
- self-amendment (X/Twitter)
- voluntary concealment of evidence
- poor management of website migration
- involuntary cancellation
- deactivation of automatic translation systems
- deactivation of automatic content generation systems
- deactivation of content aggregation systems
- variation of the page URL without appropriate redirection
In essence there is no margin to be able to use this data as an indication of the behavior of those who generate content on the web. It is also not possible to establish whether the disappearance of Internet pages, years later, whether it is good or bad. Sometimes, it's just about compliance with the law, political or personal decisions, corrections or updates. Perhaps the only valid reflection to make is the one that revolves around the responsibility of the so-called "active users" of the Internet, that is, of all those who, in one way or another, generate some of the contents of the web: be they simple contributors to the online encyclopedia "Wikipedia" or the social network X/Twitter, whether they are digital publishers or those responsible for this or that government site. Too often, these subjects complain about the difficulty in finding information on the Internet, the inconsistency of the results or worse, the unsatisfactory positioning of their favorite sources, forgetting that they themselves are part of the problem. The example of someone who, by changing the URL of a page without carrying out the appropriate redirection, only makes the Internet a worse place: a virtual world full of digital rubbish, made up of many requests that fall on deaf ears and, at the at the same time, of contents that will no longer be available. The Internet, since it was consolidated, has its own netiquette (good rules of conduct for users) which should be read and respected by everyone*.
If, in the final analysis, there was someone who believed the disappearance of Internet pages, where it was imposed, was always a bad thing, they would have to do nothing but work to ensure that change specific laws, cause of cancellation.
*see request for comments: 1855 (netiquette guidelines): “remember that setting up an information service is more than just design and implementation. It's also maintenance”.



